|
|
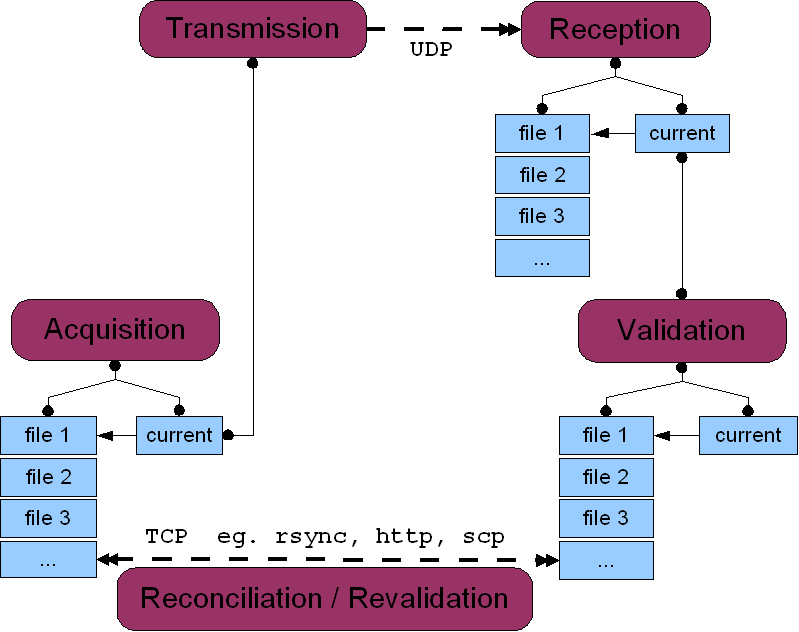
| Figure 1: Generic data flow |
|---|
The NORSTAR riometer data acquisition and telemetry process consists of six stages illustrated in Figure 1 and listed below:
This process was developed to satisfy several kinds of constraints. First, it must operate effectively over a low-bandwidth high-latency satellite internet link. Second, it needs to work with multiple legacy data streams. Third, it should require a minimum of technical expertise and programming effort.
A riometer unit at each remote field site measures the cosmic "noise" power at 30 MHz. Signal strength is converted non-linearly to voltage (0V to 7.5V) which is digitized at 60 Hz to 12 bit values spanning a -10V to 10V range. These are read by a computer over an RS-232 serial interface and time stamped using the site GPS unit as a primary NTP reference.
Values are grouped into 1-second intervals from which the average and range are calculated. Every 60 seconds a record is written to disk, where it should be noted that the record boundaries are not necessarily synchronized to minute boundaries. Each record should contain a header (20 bytes) and 60 data points (6 bytes each) for a total of 380 bytes per record.
struct data_header {
char stream_id[4]; /* should always be 'XRIO' */
char site_id[4]; /* eg. 'gill', 'RANK' (safest to fold case) */
char version; /* currently '0' */
char sample_rate; /* currently 1 (samples/second) */
char spare1[2];
long int timestamp; /* first sample in unix epoch (seconds since January 01, 1970) */
uint16_t datapoints; /* currently 60, but always check */
char spare2[2];
} __attribute__((__packed__));
struct data_point{
uint16_t a2d_average; /* should be 0 to 4095 */
uint16_t a2d_range; /* should be 0 to 4095 */
uint16_t npoints; /* usually 60, sometimes 59 or 61, flag anything else */
} __attribute__((__packed__));;
Records are appended to hourly files and grouped together in a directory tree organized by date and site. The last path element is unnecessary at each remote site, but is very useful when aggregating data from multiple sites on a central server.
[monitor@calgu riometer]$ ls /data/riometer/2006/01/17/calg_xrio/ 20060117_00_calg_xrio.dat 20060117_08_calg_xrio.dat 20060117_16_calg_xrio.dat 20060117_01_calg_xrio.dat 20060117_09_calg_xrio.dat 20060117_17_calg_xrio.dat 20060117_02_calg_xrio.dat 20060117_10_calg_xrio.dat 20060117_18_calg_xrio.dat 20060117_03_calg_xrio.dat 20060117_11_calg_xrio.dat 20060117_19_calg_xrio.dat 20060117_04_calg_xrio.dat 20060117_12_calg_xrio.dat 20060117_20_calg_xrio.dat 20060117_05_calg_xrio.dat 20060117_13_calg_xrio.dat 20060117_21_calg_xrio.dat 20060117_06_calg_xrio.dat 20060117_14_calg_xrio.dat 20060117_22_calg_xrio.dat 20060117_07_calg_xrio.dat 20060117_15_calg_xrio.dat 20060117_23_calg_xrio.dat
At each remote site, a watcher routine makes a copy of each new data record and transmits it as a single UDP packet to port 24985 on a telemetry server. (UDP is a connectionless low-overhead best-effort protocol; details can be found online eg. here or here.) Total bandwidth is roughly 51 bits/second.
A central server listens to UDP port 24895 and receives all incoming packets. There should be one packet from each of 12 sites every 60 seconds. These are appended to hourly data files named according to arrival time and destination port and organized in a directory tree by arrival date and source IP address. A current tree of all received UDP packets should be available here. The following example shows one day from a site which is transmitting two different telemetry streams on UDP ports 24985 (riometer) and 25000 (status monitor) respectively.
[bjackel@cgsm-rt udp]$ ls 2006/01/17/136.159.51.71/ ut00_24985.dat ut04_24985.dat ut08_24985.dat ut12_24985.dat ut16_24985.dat ut20_24985.dat ut00_24985.idx ut04_24985.idx ut08_24985.idx ut12_24985.idx ut16_24985.idx ut20_24985.idx ut00_25000.dat ut04_25000.dat ut08_25000.dat ut12_25000.dat ut16_25000.dat ut20_25000.dat ut00_25000.idx ut04_25000.idx ut08_25000.idx ut12_25000.idx ut16_25000.idx ut20_25000.idx ut01_24985.dat ut05_24985.dat ut09_24985.dat ut13_24985.dat ut17_24985.dat ut21_24985.dat ut01_24985.idx ut05_24985.idx ut09_24985.idx ut13_24985.idx ut17_24985.idx ut21_24985.idx ut01_25000.dat ut05_25000.dat ut09_25000.dat ut13_25000.dat ut17_25000.dat ut21_25000.dat ut01_25000.idx ut05_25000.idx ut09_25000.idx ut13_25000.idx ut17_25000.idx ut21_25000.idx ut02_24985.dat ut06_24985.dat ut10_24985.dat ut14_24985.dat ut18_24985.dat ut22_24985.dat ut02_24985.idx ut06_24985.idx ut10_24985.idx ut14_24985.idx ut18_24985.idx ut22_24985.idx ut02_25000.dat ut06_25000.dat ut10_25000.dat ut14_25000.dat ut18_25000.dat ut22_25000.dat ut02_25000.idx ut06_25000.idx ut10_25000.idx ut14_25000.idx ut18_25000.idx ut22_25000.idx ut03_24985.dat ut07_24985.dat ut11_24985.dat ut15_24985.dat ut19_24985.dat ut23_24985.dat ut03_24985.idx ut07_24985.idx ut11_24985.idx ut15_24985.idx ut19_24985.idx ut23_24985.idx ut03_25000.dat ut07_25000.dat ut11_25000.dat ut15_25000.dat ut19_25000.dat ut23_25000.dat ut03_25000.idx ut07_25000.idx ut11_25000.idx ut15_25000.idx ut19_25000.idx ut23_25000.idx
Each data file ("*.dat") has an accompanying index file ("*.idx") with one line per packet received. Each line contains information including the arrival time, source IP address, total size, offset within the data file, and the first four bytes.
[bjackel@cgsm-rt udp]$ head -n 10 2006/01/17/136.159.51.71/ut00_24985.idx 2006-01-17 00:00:06.421153 24985 136.159.51.71:32769 380 0 58 52 49 4f 2006-01-17 00:01:06.902381 24985 136.159.51.71:32769 380 380 58 52 49 4f 2006-01-17 00:02:06.375104 24985 136.159.51.71:32769 380 760 58 52 49 4f 2006-01-17 00:03:06.814618 24985 136.159.51.71:32769 380 1140 58 52 49 4f 2006-01-17 00:04:06.285830 24985 136.159.51.71:32769 380 1520 58 52 49 4f 2006-01-17 00:05:06.766924 24985 136.159.51.71:32769 380 1900 58 52 49 4f 2006-01-17 00:06:06.228161 24985 136.159.51.71:32769 380 2280 58 52 49 4f 2006-01-17 00:07:06.689275 24985 136.159.51.71:32769 380 2660 58 52 49 4f 2006-01-17 00:08:06.150479 24985 136.159.51.71:32769 380 3040 58 52 49 4f 2006-01-17 00:09:06.611591 24985 136.159.51.71:32769 380 3420 58 52 49 4f
Index files can be used for a variety of diagnostic tasks. The following example shows that only 1437 out of a possible 1440 records were received from the Dawson riometer during January 17 2004. The daily average loss rate due to these three dropped packets is just over 0.2%.
[bjackel@cgsm-rt udp]$ wc -l 2006/01/17/206.172.47.234/ut??_24985.idx
60 2006/01/17/206.172.47.234/ut00_24985.idx
60 2006/01/17/206.172.47.234/ut01_24985.idx
60 2006/01/17/206.172.47.234/ut02_24985.idx
60 2006/01/17/206.172.47.234/ut03_24985.idx
60 2006/01/17/206.172.47.234/ut04_24985.idx
60 2006/01/17/206.172.47.234/ut05_24985.idx
60 2006/01/17/206.172.47.234/ut06_24985.idx
60 2006/01/17/206.172.47.234/ut07_24985.idx
60 2006/01/17/206.172.47.234/ut08_24985.idx
60 2006/01/17/206.172.47.234/ut09_24985.idx
60 2006/01/17/206.172.47.234/ut10_24985.idx
60 2006/01/17/206.172.47.234/ut11_24985.idx
60 2006/01/17/206.172.47.234/ut12_24985.idx
60 2006/01/17/206.172.47.234/ut13_24985.idx
60 2006/01/17/206.172.47.234/ut14_24985.idx
60 2006/01/17/206.172.47.234/ut15_24985.idx
59 2006/01/17/206.172.47.234/ut16_24985.idx
60 2006/01/17/206.172.47.234/ut17_24985.idx
59 2006/01/17/206.172.47.234/ut18_24985.idx
60 2006/01/17/206.172.47.234/ut19_24985.idx
60 2006/01/17/206.172.47.234/ut20_24985.idx
60 2006/01/17/206.172.47.234/ut21_24985.idx
59 2006/01/17/206.172.47.234/ut22_24985.idx
60 2006/01/17/206.172.47.234/ut23_24985.idx
1437 total
From the same site during the entire month of December 2005 there were 125 packets missing of a possible 44640, for an average loss rate of 0.28%. Peak loss rate during the worst day (2005/12/16) was just over 2%. Most of this was in fact due to server downtime rather than network problems.
[bjackel@cgsm-rt udp]$ for i in 2005/12/*/206.172.47.234 > do echo -n $i > wc -l $i/ut??_24985.idx | grep total > done 2005/12/01/206.172.47.234 1426 total 2005/12/02/206.172.47.234 1438 total 2005/12/03/206.172.47.234 1436 total 2005/12/04/206.172.47.234 1439 total 2005/12/05/206.172.47.234 1438 total 2005/12/06/206.172.47.234 1418 total 2005/12/07/206.172.47.234 1437 total 2005/12/08/206.172.47.234 1435 total 2005/12/09/206.172.47.234 1439 total 2005/12/10/206.172.47.234 1440 total 2005/12/11/206.172.47.234 1439 total 2005/12/12/206.172.47.234 1439 total 2005/12/13/206.172.47.234 1437 total 2005/12/14/206.172.47.234 1430 total 2005/12/15/206.172.47.234 1436 total 2005/12/16/206.172.47.234 1411 total 2005/12/17/206.172.47.234 1438 total 2005/12/18/206.172.47.234 1440 total 2005/12/19/206.172.47.234 1439 total 2005/12/20/206.172.47.234 1439 total 2005/12/21/206.172.47.234 1439 total 2005/12/22/206.172.47.234 1438 total 2005/12/23/206.172.47.234 1440 total 2005/12/24/206.172.47.234 1439 total 2005/12/25/206.172.47.234 1439 total 2005/12/26/206.172.47.234 1431 total 2005/12/27/206.172.47.234 1440 total 2005/12/28/206.172.47.234 1438 total 2005/12/29/206.172.47.234 1439 total 2005/12/30/206.172.47.234 1438 total 2005/12/31/206.172.47.234 1440 total
The validation process periodically checks a set of pointers to the most recent hour files to determine when new records have arrived. Any new data are passed through an "invalidation" stage which checks for fundamental deviations from the expected data format. These currently include:

|
| Figure 2: Real-time data from Dawson |
|---|
Any record which sucessfully passes all invalidation checks is provisionally declared to be "valid". This does not guarantee that all possible errors have been found and does not imply that the record contents are necessarily correct or reliable. For example, pre-amplifier failures at a field site can result in the remote computer simply logging small voltage fluctuations within ±50 millivolts of zero. These records are certainly not scientifically useful for ionospheric studies but will be passed by the current validation algorithm.
Validated records are appended to hourly files using the same naming convention as at the remote field sites. They are also used to generate various kinds of summary information. One example is given in Figure 2, which contains a link to the most recently produced daily plot of real-time data from the Dawson field site.
If the remote transmission and central reception stages are operating over a perfect network connection then validated data files on the central server will be identical copies of those acquired at the remote field site. In reality some packets will inevitably be lost due to network problems. This will result in data gaps on the central server. Using data from Dawson on January 17 2006 as an example, the remote field site originally transmitted 1440 packets for a total of 547200 bytes. Three of these packets (1140 bytes) were never received by the central server. These three packets must somehow be retrieved in order to modify files on the central server so that they are identical to the original ones on the remote field site computer.
Ideally this would require a minimum of 3 × 380 = 1140 bytes, which is
an increase of roughly 0.2% on top of the 547200 bytes originally transmitted.
In practice some additional bytes may be required to ensure data integrity
(eg. checksums). Such increases may be balanced by using compression to reduce
the total amount of data transfered. This is illustrated by the following
example where a standard tool (xdelta) is used to determine the
differences between files on the central server and a copy of the original
files from the remote site. A total of 1241 bytes are needed to store all the
information required to fill all three gaps in the central data files.
[bjackel@cgsm-rt tmp]$ for i in remote/*.dat > do i=`basename $i` > cmp central/$i remote/$i || xdelta delta central/$i remote/$i $i.xdelta > done [bjackel@cgsm-rt tmp]$ ls -al *.xdelta -rw-rw-r-- 1 bjackel bjackel 395 Jan 18 02:01 20060117_16_daws_xrio.dat.xdelta -rw-rw-r-- 1 bjackel bjackel 430 Jan 18 02:01 20060117_18_daws_xrio.dat.xdelta -rw-rw-r-- 1 bjackel bjackel 416 Jan 18 02:01 20060117_22_daws_xrio.dat.xdelta [bjackel@cgsm-rt tmp]$ xdelta info 20060117_16_daws_xrio.dat.xdelta xdelta: version 1.1.3 found patch version 1.1 in 20060117_16_daws_xrio.dat.xdelta (compressed) xdelta: output name: 20060117_16_daws_xrio.dat xdelta: output length: 22800 xdelta: output md5: 08133801d9d416126128a5c6ec0b7091 xdelta: patch from segments: 2 xdelta: MD5 Length Copies Used Seq? Name xdelta: 0e625120c73401619e98bd8f06a059e8 296 4 296 yes (patch data) xdelta: de72c1b6abc12912abdfc2ceac8acfa9 22420 6 22504 no 20060117_16_daws_xrio.dat
In the preceeding example the comparison was carried out using copies of the "good" data. Of course, it would be preferable to somehow identify gaps without having to first download the entire data set as a reference.
One way would be to start with an understanding of the expected record cadence and try to infer which records are missing. This information could then be used to determine the range(s) of bytes required from the original file. Finally, some mechanism such as HTTP Range requests could be used to transfer the those bytes of interest from the remote site to the central server, where they could be inserted into the file gap(s).
An equivalent result can be obtained without requiring any knowledge
of the record format or rate. If the validation stage uses the same
naming convention as the original acquisition, then standard tools
can be used to synchronize the two sets of files. For example, the
rsync program automatically identifies differences between
three of the 24 hourly files and transfers the information required
to remove gaps on the central server. Due to block-size issues it
actually transfers more bytes than strictly required (3240 rather
than 1140 bytes) but with compression this is reduced considerably
(2264 bytes including overhead).
[bjackel@cgsm-rt daws_xrio]$ rsync --verbose --archive --compress --stats \ rsync://206.172.47.234/data/riometer/2006/01/17/daws_xrio/* . opening tcp connection to 206.172.47.234 port 873 receiving file list ... 24 files to consider delta transmission enabled ... Number of files: 24 Number of files transferred: 24 Total file size: 547200 bytes Total transferred file size: 547200 bytes Literal data: 3240 bytes Matched data: 543960 bytes File list size: 668 Total bytes sent: 5235 Total bytes received: 2264 sent 5235 bytes received 2264 bytes 789.37 bytes/sec total size is 547200 speedup is 72.97
It is interesting to consider the case where an entire day of data
needs to be recovered. Possible causes might include the remote satellite
dish being knocked out of alignment or a failure of the central server.
Simply using rsync without any compression would require
a transfer of the complete day of data (547200 bytes) with an additional
1664 bytes for overhead (eg. filenames, checksums, etc.).
This would require an additional 0.3% of bandwidth, which is negligible.
Using the --compress flag to enable gzip
compression before transmission produces a remarkable reduction to
110908 bytes including overhead. For this case, retrospective recovery
would use only 20% of the bandwidth required for real-time transmission.
The reconcilation stage only guarantees that the central server has data files identical to those at the remote field site. It is possible, at least in theory, that the original files were somehow corrupt in a way which would be caught by one of the invalidation checks. Consequently, the validation process should be re-applied to any files modified during reconciliation.